BUS5DWR Data Wrangling and R Report 3 Sample
Overview
This assignment allows you to demonstrate your knowledge and skills of data wrangling with Text editors and R. Please carefully read the entire assignment to make sure you understand the requirements, the submission format and marking rubrics before starting.
Specific Requirements
The data received from Vivino wine rating IT department comprises three data files: Wine.xlsx, WineRating.txt and Region.csv. The Wine.xlsx file records the information of wine list across the world which detailed information about their ratings is recorded in WineRating.txt and Region.csv records the country of each wine region.
You are asked to:
1 Import all the data from different files into three dataframes. Write R codes to fill the last three empty columns in the Wine dataframe with appropriate information provided from the other datasets. (Hint: using merge function....)
2 Assess the data and correct it if necessary.
a) Assess data in Wine data frame. (We can describe the expected output here. For example: in each column,students write R code to show: datatype, min-max value (if it is numeric). Write some sentences to describe issues in column (if necessary))
b) Correct data: write R code to fix issues in columns (if necessary)
3 Investigate the data distribution of wine price by drawing its histogram and boxplot and providing your insight.
4 The company wants to collaborate with favourite wineries to expand its market. To support managers’ decision making, you are required to:
a) Propose a ranking with at least 2 criteria to rank the wineries for the company to
choose for their next collaboration. Provide your justification.
b) Create a dataframe which contains the best wineries based on your ranking. Display the list of the wineries in the descending order of your proposed criteria, i.e., the best one first. You can consider different markets or wine types if necessary. Make the dataframe concise and comprehensive (having meaningful number of columns, column titles, appropriate data format, etc.)
5 Based on your answer to Questions 1 to 4, you come up with discussions on the outcomes and recommendations for managers on how to expand their market. Note that if this part is missing or the content of this part does not match the R file, no mark will be awarded for the whole assignment.
Solution
Data Preparation
Data preparation is a crucial initial step in any data analysis process. It thus involves several key stages, including importing the dataset, assessing its properties, specifically correcting any issues that may practically be present, and preparing the data for further analysis. Uni Assignment Help, This process predominantly ensures that the data primarily used for analysis is, therefore, reliable, accurate, and suitable for the intended purpose.
To begin with, the process of importing data primarily involves using specific functions, particularly within R, to practically load the dataset into the environment. Commonly used functions specifically practically for this purpose include `read.csv()`, `read.table()`, and even similar ones. These functions primarily allow for seamless retrieval of data from various file formats, particularly such as CSV, Excel, or text files, and also make them accessible particularly for analysis within the R environment.
After successfully importing the data, the next step is, therefore, to assess its characteristics and properties. This involves using a variety of functions to gain an initial understanding of the dataset's structure. For instance, `head()` practically provides a glimpse of the first few rows, specifically offering a preview of the data's content. Meanwhile, `summary()` delivers summary statistics primarily like mean, median, and quartiles, along with information on missing values. `str()` specifically provides a concise overview of the data's structure, specifically including the type of each variable. Finally, `dim()` offers the particular dimensions of the dataset, thereby indicating the number of rows and columns.
Following the assessment stage, it is specifically imperative to address any issues identified during the evaluation. This involves the correction of missing values, outliers, or even inconsistencies within the data. Missing values, if left unattended, can lead to biased analyses and erroneous conclusions. Strategies to practically handle missing data include imputation methods like mean imputation, median imputation, or sophisticated techniques like multiple imputation.
Outliers, on the other hand, can, therefore, significantly skew statistical analyses and machine learning models. They should thus be carefully examined to determine if they specifically represent genuine data points or erroneous entries. Depending on the context, outliers can thus be either corrected or treated separately, particularly in the analysis.
Inconsistencies in the data, such as conflicting entries or even erroneous values, should be rectified to ensure the accuracy and integrity of subsequent analyses. This may specifically involve cross-referencing primarily with external sources or consulting domain experts to validate or even correct the information.
Once the data has, therefore, been assessed and corrected, it is then practically prepared for further analysis (Balduzzi et al., 2019). This step specifically encompasses a range of activities, including data cleaning, transformation, and feature engineering. Data cleaning particularly involves tasks like standardising formats, specifically removing duplicates, and also ensuring consistency in naming conventions. Transformation may thus involve scaling variables, creating new variables, or aggregating data for specific analyses. Feature engineering, a more advanced step, specifically focuses on creating new variables or even features that better represent the underlying patterns in the data.
Data preparation is specifically an indispensable process in any data analysis endeavour. It therefore involves importing the data, thereby assessing its properties, correcting any issues, and preparing it for subsequent analyses. By diligently following these steps, analysts primarily ensure that the data used predominantly for further exploration and even modelling is accurate, reliable, and well-suited for the intended purpose. This meticulous approach specifically sets the foundation for robust and trustworthy data-driven insights and conclusions.
Data Analysis (Histogram/Boxplot)
Data Analysis (Ranking/Summarising)
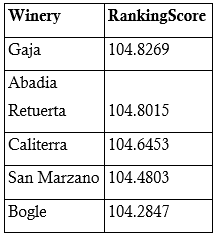
Discussion
The data analysis specifically revealed valuable insights into the performance and standing of the wineries, thereby aiding in informed decision-making specifically for potential collaborations.
The analysis practically highlighted discernible trends and patterns among the wineries. Notably, Gaja primarily emerged as the top-ranked winery, particularly with a score of 104.8269, thereby followed closely by Abadia Retuerta with a score of 104.8015. Caliterra, San Marzano, and Bogle also demonstrated specifically commendable rankings, scoring 104.6453, 104.4803, and 104.2847, respectively. This predominantly suggests a relatively narrow margin in the rankings, thereby signifying a competitive landscape in the wine industry.
The proposed ranking was therefore determined based on a combination of factors, primarily the 'RankingScore' metric. This metric primarily incorporates various attributes such as product quality, customer ratings, and other undisclosed proprietary factors. The winery with the highest 'RankingScore' was thus accorded the top position, therefore indicating superior performance specifically across these parameters.
The criteria used to rank the wineries were deliberately chosen to provide a comprehensive evaluation. This predominantly included considering customer ratings, which, therefore, serve as a reliable indicator of consumer satisfaction and product quality. The number of ratings was taken into account to gauge the wineries' popularity and even market presence. These criteria thus collectively provided a balanced assessment, thus allowing for an equitable comparison.
The implications of this ranking are specifically substantial for the company's potential collaborations. Gaja and Abadia Retuerta, thereby occupying the top two positions, stand out as strong contenders predominantly for collaboration opportunities. Their high rankings and even favourable customer ratings primarily suggest a well-established reputation and a dedicated consumer base (Gostic et al., 2020). Collaborating with these wineries could lead to mutually beneficial partnerships, therefore expanding market reach and enhancing the company's product portfolio.
The competitive landscape, primarily among the wineries, specifically underscores the importance of strategic collaborations. While Gaja and Abadia Retuerta may, therefore, hold the top positions, the relatively narrow gap in rankings predominantly indicates a dynamic industry where opportunities primarily for collaboration and growth abound. The company should leverage this competitive environment to practically explore partnerships with wineries that align specifically with its strategic objectives and target market.
The data analysis specifically provided valuable insights into the performance of the wineries, thereby facilitating informed decision-making for potential collaborations. The proposed ranking, practically based on a combination of factors, therefore offers a comprehensive evaluation of the wineries' standing. This ranking will thereby be instrumental in guiding the company's collaboration efforts, primarily ensuring strategic and mutually beneficial partnerships in the competitive wine industry.
References
Balduzzi, S., Rücker, G. and Schwarzer, G., 2019. How to perform a meta-analysis with R: a practical tutorial. BMJ Ment Health, 22(4), pp.153-160.
Gostic, K.M., McGough, L., Baskerville, E.B., Abbott, S., Joshi, K., Tedijanto, C., Kahn, R., Niehus, R., Hay, J.A., De Salazar, P.M. and Hellewell, J., 2020.
Practical considerations for measuring the effective reproductive number, R t. PLoS computational biology, 16(12), p.e1008409.
Would you like to schedule a callback?
Send us a message and we will get back to you
Main Services
- Accounting Assignment Help
- Accounting Assignment Helper
- Accounting Case Study Assignment Help
- Accounting Essay Help
- Assignment Help Adelaide
- Assignment Help Auckland
- Assignment Help Ballarat
- Assignment Help Bendigo
- Assignment Help Birmingham
- Assignment Help Brisbane
- Assignment Help Bristol
- Assignment Help Calgary
- Assignment Help Canberra
- Assignment Help Darwin
- Assignment Help Dubai
- Assignment Help Dublin
- Assignment Help Geelong
- Assignment Help Gold Coast
- Assignment Help Griffith
- Assignment Help Hamilton
- Assignment Help Hobart
- Assignment Help Liverpool
- Assignment Help London
- Assignment Help Manchester
- Assignment Help New York
- Assignment Help Newcastle
- Assignment Help Oxford
- Assignment Help Perth
- Assignment Help Sydney
- Assignment Help Toowoomba
- Assignment Help Toronto
- Assignment Help Wellington
- Assignment Writing Help
- AU
- Auditing Assignment Help
- Biology Assignment Help
- Bond University Assignment Help
- Business Accounting Assignment Help
- Buy Research Paper
- CA
- Case Study Help
- Corporate Accounting Assignment Help
- Cost Accounting Assignment Help
- Coursework Writing Help
- Curtin University Assignment Help
- Deakin University Assignment Help
- Dissertation Writing Help
- Do My Accounting Assignment
- Do My Accounting Papers
- Do My Finance Assignment
- Economics Assignment Help
- Engineering Assignment Help
- Essay Writing Help
- Federation University Assignment Help
- Finance Assignment Help
- Financial Planning Assignment Help
- Flinders University Assignment Help
- Holmes Institute Assignment Help
- Humanities Assignment Help
- IT Assignment Help
- JCU Assignment Help
- Kaplan Business School Assignment Help
- La Trobe University Assignment Help
- Law Assignment Help
- Leader Institute Assignment Help
- Management Assignment Help
- Managerial Accounting Assignment Help
- Mathematics Assignment Help
- Monash University Assignment Help
- MY
- Nursing Assignment Help
- NZ
- PIA University Assignment Help
- Programming Assignment Help
- Queensland University of Technology Assignment Hel
- Research Paper Help
- Research Paper Writers
- Research Paper Writing Help
- Research Paper Writing Service
- RMIT University Assignment Help
- Science Assignment Help
- SG
- Swinburne University of Technology Assignment Help
- Thesis Writing Help
- UAE
- UK
- UNSW Assignment Help
- US
- Victoria University Assessment Help
- VIT University Assignment Help
- Write My Assignment
- Write My Research Paper

Highlights
Earn While You Learn With Us
Confidentiality Agreement
Money Back Guarantee
Live Expert Sessions
550+ Ph.D Experts
21 Step Quality Check
100% Quality
24*7 Live Help
On Time Delivery
Plagiarism-Free
Our Samples
- ES5702 Planetary Health and Climate Change Report Sample
- OPS910 Linear Programming Assignment Sample
- MBA602 Small Business Administration Case Study 2 Sample
- MIS500 Foundations of Information Systems Report 1 Sample
- ACC202 Contemporary Financial Accounting Report Sample
- MG304 Agriculture Value Chain Management Case Study 2 Sample
- HWEL2006 Social and Emotional Wellbeing Case Study 3 Sample
- ICT606 Machine Learning Report Sample
- DATA6000 Capstone: Industry Case Studies Report Sample
- MIS607 Cybersecurity Report 3 Sample
- M20467 Strategic Management Coursework Sample
- MGNT803 Organisational Behaviuor and Management Report Sample
- ICC104 Introduction to Cloud Computing Report 2 Sample
- MIS610 Advanced Professional Practice Report 2 Sample
- MIS604 Requirements Engineering Case Study 1 Sample
- MBA504 Introduction to Data Analytics for Business Case Study 1 Sample
- BUS5003 Information Systems and Data Analysis Case Study 2 Sample
- ECE6003 Contemporary Issues, Social Contexts of Learning and Social Justice Sample
- MGT613 Leadership for Sustainable Futures Report Sample
- MBA402 Governance, Ethics and Sustainability Report 3 Sample
- MBA633 Real-world Business Analytics and Management Report 2 Sample
- NURBN3031 Teaching, Learning and Situational Leadership for Health Practice Sample
- MIS608 Agile Project Management Case Study 3 Sample
- INFS5023 Information Systems for Business Case Study Sample
- ECON7200 Economic Principles Report Sample
- DATA4000 Introduction to Business Analytics Report 2 Sample
- FIN311 Agricultural Accounting and Business Law Part A Report Sample
- MECO6912 Political Public Relations Report 1 Sample
- MIS605 Systems Analysis and Design Assignment 1 Sample
- PUBH6008 Capstone A Applied Research Project in Public Health Report Sample
- MIS611 Information Systems Capstone Report 1 Sample
- CA7013 Sustatnability in Global Companies 2022-23 Report
- ICC104 Introduction to Cloud Computing Report 3 Sample
- BUS101 Business Communication Essay 3 Sample
- ISYS1005 Systems Analysis and Design Report 3 Sample
- BULAW5916 Taxation Law and Practice Assignment Sample
- HDW204 Healthcare in the Digital World Report 2 Sample
- BUS5DWR Data Wrangling and R Report 3 Sample
- HI5029 IS Project Management Report Sample
- COIT20249 Professional Skills in Information Communication Technology Report 2 Sample
- MGT502 Business Communication Report 2 Sample
- OMGT2327 Distribution and Freight Logistics Case Study 1 Sample
- PPMP20009 Case Study Sample
- COIT20253 Business Intelligence using Big Data Report Sample
- MCR001 Economics Case Study Sample
- TECH1300 Information Systems in Business Case Study 2 Sample
- OPS928 Logistics Systems Assignment Sample
- MIS608 Agile Project Management Report 4 Sample
- MBIS5009 Business Analytics Report Sample
- MBIS5010 Professional Practice in Information Systems Case Study 3 Sample
- NURS2021 Dimensions of Physical and Mental Health Case Study 3 Sample
- HA3011 Accounting Report Sample
- NURBN3030 Management of Deteriorating Patient Report Sample
- Written Assessment Report 2 Sample
- CAP203 Care of The Person With An Acute Illness Report 4 Sample
- Critically Examine and Identify the Issues within The Case Study from a Legal and Ethical Perspectiv
- BM303 Contemporary Issues in Agribusiness Production and Management Case Study Sample
- MBA5004 Managing Decision Making Process Report 2 Sample
- Strategic and Operating Health Management Report 2 Sample
- BULAW5915 Corporate Law Assignment Sample
- HI5017 Managerial Accounting Report Sample
- MBA600 Capstone Strategy Essay 3 Sample
- NURBN2022 Case Study 3 Sample
- CAS101 Community Development Report 2 Sample
- TECH2400 Introduction to Cyber Security Report 1 Sample
- MBIS5010 Professional Practice in Information Systems Essay 2 Sample
- HDW204 Healthcare in the Digital World Report 1 Sample
- PRJ5108 Project Delivery and Procurement Case Study 4 Sample
- PRJ5106 Research Methodology and Data Analysis Assignment 2 Sample
- PRJ6001 Applied Project Report 1 Sample
- MGT502 Business Communication Report 1A Sample
- MEM601 Engineering Sustainability Report Sample
- Planning in Health and Social Care Essay Sample
- COIT20248 Information Systems Analysis & Design Report 1 Sample
- ECUR302 Mathematics in the Early Years Report Sample
- MC7080 Digital Marketing & Social Media Report Sample
- MBA404 Consumer Behaviour and Marketing Psychology Report 3 Sample
- MBA6204 Managing the Quantitative Support of Decision Making Report 2 Sample
- DATA4700 Digital Marketing and Competitive Advantage Report 3 Sample
- MBA404 Consumer Behaviour and Marketing Psychology Report 1 Sample
- Finance Mini Case Study Sample
- MBA6302 Integrated Marketing Communications Report Sample
- SWOT Analysis of Chanel No5 Perfume Marketing 4ps Report
- MIS610 Advanced Professional Practice Report 2 Sample
- Principles of Economics Assignment Sample
- OPS802 Operations Management of Subway Research Report 4 Sample
- EDU20014 Social and Emotional Learning Report Sample
- TUM202 Therapeutic use of Medicines Report 2 Sample
- NURBN2023 Pathophysiology and Pharmacology Applied to Person-Centred Nursing Essay Sample
- MIS603 Microservices Architecture Report 3 Sample
- MITS4001 Business Information Systems Case Study 3 Sample
- MGT601 Dynamic Leadership Report 1 Sample
- CAP203 Care of the person with an acute illness Case Study 2 Sample
- TECH2300 Service and Operations Management in IT Case Study 2 Sample
- TCHR3001 Early Childhood Matters Report 2 Sample
- MBA505 Business Psychology Coaching and Mentoring Report Sample
- MIS608 Agile Project Management Report 2 Sample
- BUS5VA Visual Analytics Report 3 Sample
- CPO442 Cybersecurity Principles and Organisational Practice Report 2 Sample
- DATA4900 Innovation and Creativity in Business Analytics Report 4 Sample
- Personal Improvement Plan Report Sample
- MBA402 Governance, Ethics and Sustainability Report 3 Sample
- DATA4900 Innovation and Creativity in Business Analytics Report 3 Sample
- INT102 Assessment 1B Improving Communication with Vision-Impaired People Case Study Sample
- GAL613 Grief and Loss Essay Sample
- PRJ5001 Project Management Profession Report Sample
- PBHL20001 Understanding Public Health Essay 3 Sample
- BUS102 Management Principles Essay 2 Sample
- HEAL5004 Strategic and Operational Health Services Management Report 3 Sample
- ECX2953/ECX5953 Economics Essay Sample
- Social Media Audit Details Report Sample
- MBA6301 Event Management Report 3 Sample
- CMT218 Data Visualisation Case Study Sample
- MN7002 International Business Strategy Report Sample
- EDU10005 Indigenous Education and Perspectives Essay 2 Sample
- GDECE102 Learning and Development Birth To Two Years Report 1 Sample
- DSMG29001 Disaster Risk Reduction Report Sample
- TECH5300 Bitcoin Report 2 Sample
- MIS608 Agile Project Management Report 2 Sample
- MIS609 Data Management and Analytics Case Study 1 Sample
- MOB6110 Creating Entrepreneurial Leaders Report Sample
- DATA4400 Data-driven Decision Making and Forecasting Report 3 Sample
- AC400 Agribusiness Accounting Report 2 Sample
- TEC100 Introduction to Information Technology Report 2 Sample
- MBA504 Introduction to Data Analytics for Business Report 3 Sample
- ICT5151 Data and Information Management Report 4 Sample
- MBIS4008 Business Process Management Report 2A Sample
- ECUR207 Early Childhood Teacher Report Sample
- TO5103 Global Destination Competitiveness Report Sample
- MITS4004 IT Networking and Communication Report Sample
- Information Security Assignment Sample
- MBA613 Organisational Change and Innovation Case Study 3 Sample
- BPM Final Assignment Sample
- MITS5502 Developing Enterprise Systems Report Sample
- ECE6012 Professional Practice Report 1 Sample
- OPS928 Logistics Systems Assignment Sample
- MLC707 Business Law Assignment Sample
- OPS909 Total Quality Management Report Sample
- MN7001 Summative Assessment 2 Report Sample
- ICT504 IT Project Management Report 2 Sample
- MIS605 Systems Analysis and Design Report Sample
- BSBPMG535 Manage Project Information and Communication Business Documents Diploma Sample
- NURBN2021 Nursing Essay Sample
- BAO6504 Accounting For Management Report Sample
- MIS100 Information Systems Case Study 2 Sample
- Australian Migration Law Assignment Sample
- HI6008 Business Research Project Report Sample
- BST714 Strategic and Operational Decision-Making Assignment Sample
- BLCN29001 Construction Technology Report Sample
- DATA4000 Introduction to Business Analytics Report 3 Sample
- 32144 Technology Research Preparations Report 2 Sample
- EC400 Agribusiness Economics and Finance Case Study 3 Sample
- BUACC5931 Research and Statistical Methods for Business Assignment Sample
- OPS928 Logistics Systems Report 2 Sample
- ACF5956 Advanced Financial Accounting Report Sample
- CSE2AIF/CSE4002 Artificial Intelligence Fundamentals Report Sample
- ENEG11005 Introduction to Contemporary Engineering Report Sample
- MBA6201 Quality Management Essay Sample
- BUECO5903 Business Economics Assignment Part B Assignment Sample
- MGT602 Business Decision Analytics Report Sample
- TO5103 Global Destination Competitiveness Report Sample
- MBIS4008 Business Process Management Report Sample
- PPMP20009 Control Charts and Process Mapping Assignment Sample
- BIZZ201 Accounting for Decision Making Report Sample
- MIS775 Decision Modelling for Business Analytics Report Sample
- MGT501 Business Environment Report Sample
- MBA501 Dynamic Strategy and Disruptive Innovation Case Study 1 Sample
- Impact of Green Supply Chain Management on The Profitability of The Retail Industry Sample
- Child Development Case Study Sample
- DSMG2002 Exploring Emergency in Disaster Management Research Report 1 Sample
- ENGR8931 Geotechnical Engineering GE 1st Copy Sample
- Journal of Co-operative Organization and Management Sample
- MITS5004 IT Security Research Report 2 Sample
- AT3 Nursing Case Study Sample
- DATA4600 Business Analytics Project Management Case Study 1 Sample
- MGT600 Management People and Teams Report 1 Sample
- Journal Article Review Report 4 Sample
- MBA641 Strategic Project Management Report Sample
- MITS5003 Wireless Networks and Communication Case Study Sample
- LAW6001 Taxation Law Case Study Sample
- ACC4001 Accounting Principles and Practices Assignment Sample
- ACC602 Financial Accounting and Reporting Report 4 Sample
- OPS911 Strategic Procurement Management Report Sample
- EASC2702 Global Climate Change Report Sample
- MBA504 Introduction to Data Analytics for Business Case Study 2 Sample
- Investigating The Issue of Inequality in Workplaces Essay Sample
- MITS6004 Enterprise Systems Report 1 Sample
- EC102 Agricultural Economics Assignment Sample
- BUS2003 Data Engineering & Python Report 1 Sample
- ENEG28001 Australian Engineering Practice Report 1 Sample
- TECH8000 IT Capstone Report Sample
- EDU30059 Teaching Technologies Report 2 Sample
- PROJ6000 Principles of Project Management Report Sample
- CS4417 Software Security Report Sample
- M5011 Accounting for Management Report Sample
- MBIS4009 Professional Practice in Information Systems Essay Sample
- NURBN1016 Primary Health Essay 2 Sample
- INT103 Human Development Across the Lifespan Report 2 Sample
- MBA6104 Business Process Modelling & Management Report Sample
- TECH2200 IT Project Management Case Study 1 Sample
- MGT502 Business Communication Report 1B Sample
- TECH2200 IT Project Management Report 2 Sample
- Clinical Governance Essay 1 Sample
- MIS500 Foundations of Information Systems Report Sample
- MGT607 Innovation Creativity Entrepreneurship Case Study Sample
- Marketing Assignment Writing Sample
- BE485 Management and Strategy Report Sample
- ICT80011/40005 Energy Storage System Report Sample
- MBA401 People, Culture and Contemporary Leadership Report Sample
- Management Essay Sample
- BRM5002 Intercultural Awarness for Business Report Sample
- MCR006 Financial Management Assignment 3 Sample
- TECH2100 Introduction to Information Networks Report 2 Sample
- DATA4500 Social Media Analytics Case Study Sample
- MBA622 Comprehensive Healthcare Strategies Report 1 Sample
- Principles of Supply Chain Management Report Sample
- MBA633 Real-world Business Analytics and Management Case Study Sample
- MBA503 Operations Management and Decision-Making Models Report 3 Sample
- ACCT6007 Financial Accounting Theory and Practice Report 2 Sample
- PROJ-6012 Managing Information Systems, Technology Report Sample
- OPS802 Operations Management Report 3 Sample
- MBA673 Business Analytics Life Cycle Report 2 Sample
- MGT610 Organisational Best Practice Case Study 2 Sample
- MBIS5012 Strategic Information Systems Report Sample
- DATA4300 Data Security and Ethics Report 1 Sample
- MANM399 International Accounting and Finance Project Report Sample
- MOB6110 Creating Entrepreneurial Leaders Report Sample
- HI5004 Marketing Management Assignment Sample
- MKTG6002 Marketing Report 3 Sample
- MIS610 Advanced Professional Practice Report 3 Part A Sample
- MANM376 International Finance Project Report Sample
- BSBOPS601 Develop and Implement Business Plan Diploma Sample
- OPS909 Total Quality Management Report 1 Sample
- INFS2036 Business Intelligence Report 1 Sample
- Organisational Behaviour (OB) Essay Sample
- TECH2300 Service and Operations Management in IT Report 3 Sample
- AHS205 The Australian Healthcare System within a Global Context Report 2 Sample
- BUS6302 Integrated Marketing Communications Report 1 Sample
- HCT343 Research Methods and Data Analysis Report Sample
- PRJ5001 Project Management Profession Case Study 3 Sample
- MIS605 Systems Analysis and Design Report 2 Sample
- PSYC2017 Personality and Individual Differences Research Report Sample
- MEM603 Engineering Strategy Report 2 Sample
- TECH3200 Artificial Intelligence and Machine Learning in IT Report 3 Sample
- Group of People Holding Papers Discussing White Laptop White Background Sample
- COIT20262 Advanced Network Security Report 2 Sample
- MIS603 Microservices Architecture Case Study Sample
- NURBN2026 Person Centered Nursing Sample
- Rich Picture CATWOE and Root Definition Report Sample
- BIS3006 IS Capstone Industry Project B Report Sample
- COIT20249 Professional Skills in Information Communication Technology Report2 Sample
- MBA6204 Quantitative Support of Decision Making Report 2 Sample
- COIT20252 Business Process Management Report 3 Sample
- TECH2100 Introduction to Information Networks Report 3 Sample
- STAT2009 Statistics for Managerial Decision Assignment Sample
- PPMP20008 Initiating and Planning Projects Report 3 Part B Sample
- EMS5RCE Risk Engineering Report 2 Sample
- ACCM4400 Auditing and Assurance Report Sample
- BUS2008 Strategic Planning Report Sample
- DATA4000 Introduction to Business Analytics Case Study 1 Sample
- 6006MHR Project Management Report Sample
- MBA5008 Business Research Methods Report Sample
- Economics for Business Assignment Sample
- CHM108 Introduction to Business Law Report 1 Sample
- MBA600 Capstone Strategy Essay 3 Sample
- EDU20014 Social and Emotional Learning Report Sample
- MIS611 Information Systems Capstone 3 A Report Sample
- MGT607 Innovation, Creativity & Entrepreneurship Case Study Assignment Sample
- MBA5008 Business Research Methods Report 2 Sample
- DATA4400 Data-driven Decision Making and Forecasting Report 3 Sample
- TECH1400 Database Design and Management Case Study Sample
- MIS604 Requirement Engineering Report 1 Sample
- MBA6204 Quantitative Support of Decision Making Report 3 Sample
- MBA6001 Investment Management Report 2 Sample
- PUBH6008 Capstone A Applied Research Project in Public Health Report 2 Sample
- HCCSSD102 Person Centred Practice Report 1 Sample
- MBA5008 Business Research Methods Case Study 3 Sample
- MEE80003 Automation Strategy Case Study Sample
- MIS604 Requirement Engineering Report 3 Sample
- MGT605 Business Capstone Project Report 1 Sample
- MBA642 Project Initiation, Planning and Execution Report Sample
- MGT602 Business Decision Analytics Report 3 Sample
- MBA600 Capstone Strategy Report 2 Sample
- TECH2200 IT Project Management Case Study Sample
- Enem28001 fea for engineering design report sample
- TECH2400 Introduction to Cyber Security Report 2 Sample
- TCHR5003 Principles and Practices in Early Childhood Education Assignment Sample
- BIZ102 Understanding People and Organisations Report 3 Sample
- MBA623 Healthcare Management PPT Sample
- INT101 Introduction to International Relations and Politics Essay Sample
- HI6032 Leveraging IT for Business Advantage Report 1 Sample
- HI5031 Professional Issues in IS Ethics and Practice Case Study Sample
- CWB103 Interpersonal and Intercultural Negotiation Assessment 1 Sample
- ETCH304 Diverse Literacy and Numeracy Learners Report 1 Sample
- NUR2023 Pathophysiology, Pharmacology, and Nursing Management Case Study 2 Sample
- COIT20253 Business Intelligence using Big Data Report 1 Sample
- HCCSSD103 Mental Health Case Study 3 Sample
- MBA402 Governance, Ethics and Sustainability Report 2 Sample
- CCS103A Counselling and Communication Skills Report Sample
- FIN600 Financial Management Case Study Sample
- MBA404 Consumer Behaviour and Marketing Psychology Case Study 2 Sample
- MBA404 Consumer Behaviour and Marketing Psychology Report Sample
- FIT5057 Project Management Case Study 1 Sample
- MBA643 Project Initiation, Planning and Execution Report Sample
- BUMKT5902 Marketing Mix Strategy Report Sample
- MBA401 People, Culture and Contemporary Leadership Report 3 Sample
- BE489 Analysing Organizations in the International Report Sample
- ACCY801 Accounting and Financial Management Report 2 Sample
- BUS5PB Principles of Business Analytics Report 1 Sample
- Recovery Nursing Care Plan Case Study Sample
- TECH8000 IT Capstone Report 1 Sample
- FE7066 Data Analysis for Global Business Coursework Sample
- CAO107 Computer Architecture & Operating Systems Report 2 Sample
- TECH4100 UX and Design Thinking Report 2 Sample
- MBA601 Fundamentals of Entrepreneurship Case Study 2 Sample
- CCB102 Multimedia Design Report 1 Sample
- WPDD202 Webpage Design and Development Report 4 Sample
- SITHCC001 Use Food Preparation Equipment Assignment 2 Sample
- DATA6000 Capstone Industry Case Studies Sample
- Business Management Report Sample
- FINM4100 Analytics in Accounting, Finance and Economics Report 2 Sample
- NURBN1012 Legal & Ethical Decision Making in Person Centred Care Sample
- Health and Social Care in Emergencies and Disasters Report 3 Sample
- PRJ5106 Research Methodology and Data Analysis Report 4 Sample
- Local Government Area LGA Essay 2 Sample
- ACCT6006 Auditing Theory and Practice Case Study Sample
- MIS609 Data Management and Analytics Case Study 3 Sample
- MN691 Research Methods and Project Design Report Sample
- BE969 Research Methods in Management and Marketing Sample
- DATA4000 Introduction to Business Analytics Case Study 1 Sample
- MG301 Agriculture and Resource Policy Case Study Sample
- ENEG11005 Introduction To Contemporary Engineering Report Sample
- MCR007 Understanding Project Management Essay 1 Sample
- SBM3204 Sustainability and Ethics Case Study Sample
- EDU40002 Play and Environment Report 2 Sample
- ECON20039 Economics for Managers Report 2 Sample
- Information Security PG Assignment Sample
- MGT604 Strategic Management Report 3 Sample
- MITS6002 Business Analytics Research Report Sample
- HI6034 Enterprise Information Systems Report Sample
- DHI401 Digital Health and Informatics Report 2 Sample
- COU101 Theories of Counselling Essay Sample
- MBA6103 Agile Methodology Research Report 2 Sample
- GDECE103 Language and Literacy in the Early Years Report 2 Sample
- MIS602 Data Modelling and Database Design Report 1 Sample
- DATA4000 Introduction to Business Analytics Report 3
- MIS608 Agile Project Management Report 1 Sample
- M33117 Public Policies and Labour Markets Report Sample
- PLM Principles of Logistics Management Report Sample

 81 Isla Avenue Glenroy, Mel, VIC, 3046 AU
81 Isla Avenue Glenroy, Mel, VIC, 3046 AU



